
𝗘𝗧𝗟 => 𝗘𝘅𝘁𝗿𝗮𝗰𝘁 | 𝗧𝗿𝗮𝗻𝘀𝗳𝗼𝗿𝗺 | 𝗟𝗼𝗮𝗱
Event-Driven Serverless ETL Pipelines is a data processing architecture that is used to process large amounts of data in real-time.
Here data is processed as soon as it is generated, rather than being stored and processed later.
This allows for faster processing times and more efficient use of resources.
Here are the steps involved in building an event-driven serverless ETL pipeline:
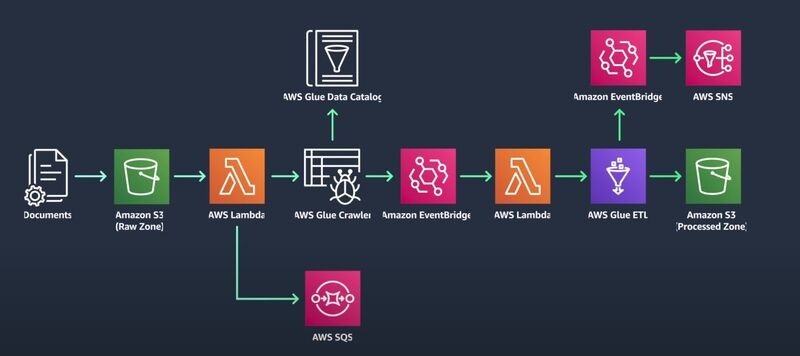
📌 𝗦𝘁𝗲𝗽 𝟭: 𝗗𝗮𝘁𝗮 𝗜𝗻𝗴𝗲𝘀𝘁𝗶𝗼𝗻
————————————
– The journey begins with the ingestion of data into a scalable data store like Amazon S3
– Here Amazon S3 serves as the primary data store for all your data. 📊🗂️
📌 𝗦𝘁𝗲𝗽 𝟮: 𝗗𝗮𝘁𝗮 𝗖𝗮𝘁𝗮𝗹𝗼𝗴𝗶𝗻𝗴
————————————–
– Next, the ingested data needs to be cataloged based on its schema.
– This is where AWS Glue Data Catalog comes into play
– It automate and scale this process while applying security access rules. 🛡️🔐
📌 𝗦𝘁𝗲𝗽 𝟯: 𝗧𝗿𝗶𝗴𝗴𝗲𝗿𝗶𝗻𝗴 𝗗𝗮𝘁𝗮 𝗣𝗿𝗼𝗰𝗲𝘀𝘀𝗶𝗻𝗴
——————————————————–
– To avoid paying for idle resources, the data processing is triggered upon data arrival in the S3 bucket using AWS Lambda function.
– This function starts an AWS Glue crawler that catalogs the data. 🔄🚀
📌 𝗦𝘁𝗲𝗽 𝟰: 𝗠𝗮𝗻𝗮𝗴𝗶𝗻𝗴 𝗟𝗮𝗿𝗴𝗲 𝗩𝗼𝗹𝘂𝗺𝗲𝘀 𝗼𝗳 𝗗𝗮𝘁𝗮
————————————————————
– To manage large volumes of Amazon S3 triggered invocations, Amazon SQS is used
– Ensuring the ETL data pipeline can run jobs in parallel when required. 📈🚀
📌 𝗦𝘁𝗲𝗽 𝟱: 𝗦𝘁𝗮𝗿𝘁𝗶𝗻𝗴 𝘁𝗵𝗲 𝗘𝗧𝗟 𝗝𝗼𝗯
———————————————-
– Once the AWS Glue crawler finishes storing metadata in the AWS Glue Data Catalog, a second Lambda function can be invoked using an Amazon EventBridge event rule.
– This function starts an AWS Glue ETL job to process and output data into another Amazon S3 bucket. 🔄🎯
📌 𝗦𝘁𝗲𝗽 𝟲: 𝗠𝗼𝗱𝗶𝗳𝘆𝗶𝗻𝗴 𝘁𝗵𝗲 𝗘𝗧𝗟 𝗝𝗼𝗯
————————————————
– The ETL job can be modified to achieve objectives like more granular partitioning, compression, or enriching of the data.
– The result?
– An event-driven, scalable, and highly automated ETL data pipeline with no servers or underlying infrastructure to manage! 🎉🚀
📌 𝗦𝘁𝗲𝗽 𝟳: 𝗡𝗼𝘁𝗶𝗳𝗶𝗰𝗮𝘁𝗶𝗼𝗻
———————————-
– Finally, as soon as the ETL job finishes, another EventBridge rule sends an email notification using an Amazon Simple Notification Service (SNS) topic
– This indicates that your data was successfully processed. 📧🔔
I hope you liked this post, follow me for more such technical content around Data Engineering and AWS Cloud
#dataengineering #awsdataengineer #bigdata #etl

Leave a comment